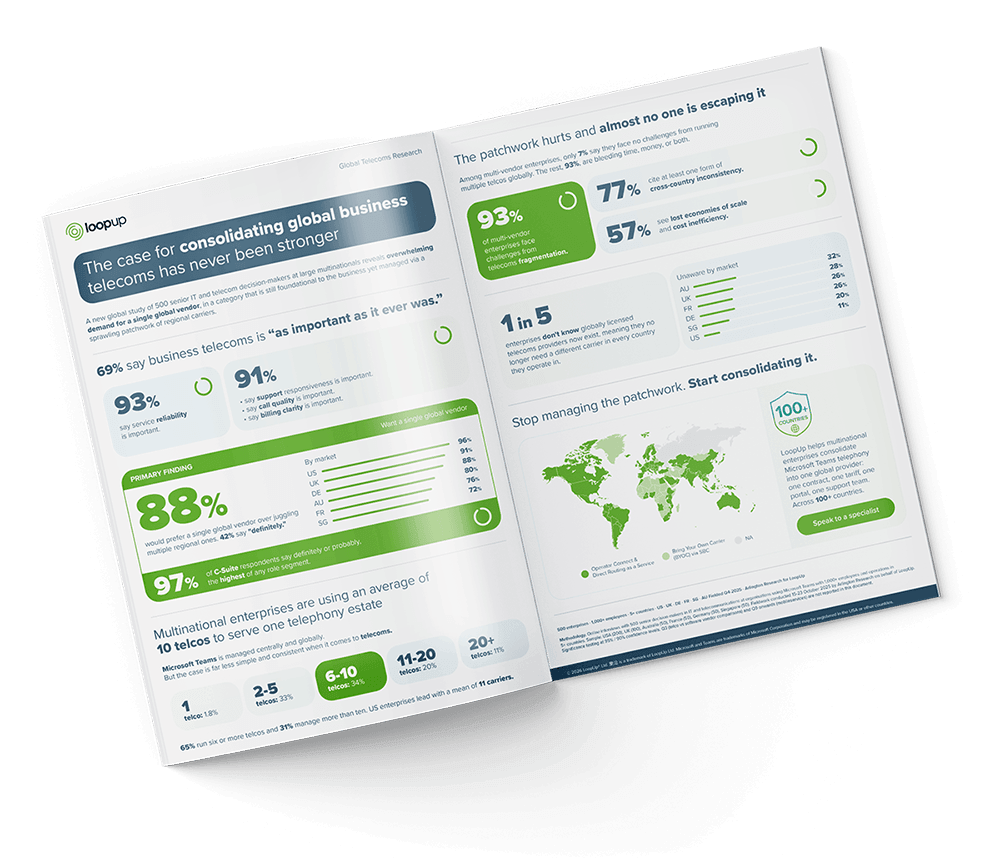
Vendors may offer impressive uptime SLAs – but how do they translate into real-world performance? Jason Sloan considers the factors that organizations should really focus on to optimize performance.
Moving telephony to the cloud can be a wonderful thing – especially in this day and age when working from home has become the norm rather than the exception. However, in order for the benefits to be fully realized, the reliability and resilience of cloud services is absolutely vital. Any lapse in uptime could have a significant impact on the quality of service cloud telephony customers can deliver to their own clients and the efficiency and effectiveness with which their business operates.
In this post we consider the two critical issues organizations need to think about to ensure maximum uptime: 1) the quality of cloud vendor service provision; and 2) what factors customers can control themselves internally within their own systems to underpin uptime performance.
It can be tempting for prospective cloud telephony customers to take the uptime guarantees given in vendors’ Service Level Agreements (SLAs) at face value without critical evaluation, while overlooking altogether the need to optimize their own corporate network. Doing either could be a mistake.
1. Deep-dive into SLAs: Understanding what vendors’ uptime guarantees really mean
When evaluating the pros and cons of different cloud telephony vendors, the Service Level Agreements (SLAs) on offer are, understandably, often seen as a major competitive differentiator. SLAs are where vendors define what level of uptime they will guarantee for their services.
You’ll see a variety of different published SLA uptime guarantees depending on the cloud vendor in question, and they will cite impressive sounding numbers such as:
- 99.999% uptime (or)
- 99.995% uptime (or)
- End-to-End 99.999% uptime guaranteed (or)
- “5 9’s” guaranteed
Essentially, the thinking goes that the more 9s, the better the service in reliability terms. However, what does that actually mean? Putting this into some sort of context matters because although uptime guarantees provide for compensation in the event of downtime, most organizations would far rather have a reliable service than a payout.
By digging a little deeper and asking some searching questions of vendors, customers may be able to establish more accurately:
- How robust is the vendor’s infrastructure?
What is the vendor’s datacenter footprint like and what sort of connectivity do they use between datacenters? Vendors with more servers in more global locations who have their own dedicated WANs should be better placed to offer a more resilient service than those without, who may have to use the public internet at times. Those who have the requisite infrastructure to get traffic off corporate WANs onto their own WAN faster are likely to be in a better position in terms of resilience.
- What has been the vendor’s historic uptime performance?
This is likely to be the most reliable gauge of uptime consistency and an indicator of future resilience. - How does the vendor measure uptime?
This may be subjective: for instance, how long does the service have to be down before the guarantee is triggered?
- What compensation does the vendor offer for failing to meet their uptime SLA?
Some vendors may be significantly more generous than others in the level of payments they will offer. This may form part of negotiations.
Being able to benchmark all these factors is important if customers are to make objective service comparisons. If vendors do not share this information upfront, customers should press them to do so. The answers will be critical to informed decision-making. What’s more, openness is likely to inspire confidence and help build good client/vendor relationships.
2. Uptime starts at home: Optimizing corporate network connectivity
Guarantees covering end-to-end uptime should also be viewed with caution. SLAs can only guarantee uptime on the network that cloud telephony vendors control. At some point, user traffic will inevitably have to use another network, whether that’s an internal office system or a remote users’ wif-fi or home ISP. End-to-end uptime is essential – but is it really possible to say that it is within a cloud vendor’s capabilities alone to deliver it? Doubtful.
If organizations are to achieve optimal uptime, the reliability of their corporate network has to be as good as that of the cloud.
If it isn’t, then that impressive-sounding guarantee that you’ve been given could become largely irrelevant. For example, if a vendor delivers 99.995% uptime, but the customer’s own network only achieves 99.9%, then it’s 20 times more likely that a service issue is caused by the customer network than by the vendor.
Therefore, your organization needs to have excellent LAN/WAN connectivity to transmit traffic as quickly and reliably as possible to the cloud provider’s network. You also need to ensure there are no infrastructure issues at your end (such as router, switch or wi-fi failures) that would prevent you from consuming cloud telephony vendors’ services correctly, though no fault of theirs.
Shared responsibility
This is where the “shared responsibility for cloud computing” model comes into play, where both the vendor and the organization using the cloud telephony services are responsible for maintaining uptime for these services.
Cloud telephony vendors provide SaaS (Software as a Service) applications, so that your organization no longer has to host applications in your own internal controlled environment i.e. on in-house servers using your own LAN/WAN network connectivity.
However, while the vendor is responsible for ensuring its service is responsive to incoming requests, you are still responsible for your internet connection and the effectiveness of your user endpoints, such as headsets or handsets.
We can divide shared responsibility into four major categories:

To maximize uptime, it’s crucial to ensure that none of these four points along the way are creating a ‘weak link’ – and if a weak link is found, it must be addressed.
From an internal customer perspective, that means taking a proactive approach to ensure that uptime is supported by a high quality internal corporate network infrastructure where reliability is equal to that of the cloud provider’s network infrastructure itself.
This could range from configuring the system to avoid unnecessary steps or blockages, such as proxy servers or virtual private networks (VPNs) so that traffic gets into the vendor’s infrastructure without delay or interference, to providing high-quality headsets to improve the user experience via seamless compatibility with application functionality. And it also means keeping a close eye on performance to ensure that optimal network connectivity is consistently maintained, developing a framework to set out what resilience and reliability factors should be monitored, and how they should be measured.
Summary
Cloud telephony uptime requires a two-pronged approach: critically considering which vendor in fact offers the best option in real terms, which must be sufficiently well-defined (the number of 9s in its SLA notwithstanding); and taking a long hard look at the important part the corporate network plays in all of this.
Proactivity is key. Vendors should be challenged to set out their stall more clearly in terms of how they quantify and deliver service reliability and the amount of downtime compensation they will offer. And internally there should be an expectation that the high levels of uptime cloud providers promise will be matched on the corporate network.
Implementing cloud telephony solutions without doing these checks and balances could lead to organizations paying for “guaranteed” uptime that is not realistically achievable, and failing to get compensation if it isn’t. There’s more to making it in the cloud than vendor SLAs.
If you’re considering embracing cloud telephony services, start those internal and external conversations early. And come and talk to us for guidance and support along the way. We can help define what customer success looks like in the cloud, advise on what questions to ask, and what measures may need to be put in place to optimize uptime. Given all the factors to take into account, it’s good to have someone on your side.
Top tips to ensure end-to-end uptime
- Identify all the factors which could impact service uptime and define who is responsible for them
- Critically evaluate vendor SLAs on an objective basis, including the robustness of their infrastructure, historic performance, the basis on which they measure up/downtime and the generosity of their compensation
- Set high expectations internally to ensure that the performance of the corporate network is consistently and proactively being optimized
- Set out a framework to define how performance should be managed and measured, so that weak links are spotted early and addressed
Jason Sloan is a Senior Director for North America at LoopUp. A Microsoft Certified Master with extensive Teams expertise, he has designed and deployed Microsoft Voice platforms for some of the world’s largest Fortune 500 companies, and had several projects showcased at the Microsoft Ignite Conference.